
| Day | Date | Time | Title |
|---|---|---|---|
| 1 | 2026-05-07 | 09:00 - 09:30 | Welcome and Introduction to Research Data Management |
| 1 | 2026-05-07 | 09:30 - 10:30 | Project & Data Organization |
| 1 | 2026-05-07 | 10:30 - 11:30 | Data Management Plans (DMPs) |
| 1 | 2026-05-07 | 11:30 - 12:30 | Lunch Break |
| 1 | 2026-05-07 | 12:30 - 13:30 | Command Line |
| 1 | 2026-05-07 | 13:30 - 14:30 | Best practices for rectangular data |
| 1 | 2026-05-07 | 14:30 - 16:00 | Brain Imaging Data Structure (BIDS) |
Introduction to Research Data Management
Research Data Management for Psychology and Neuroscience
Course at Julius-Maximilians-Universität Würzburg, RTG 2660: Approach-Avoidance
Slides | Source
![]()
09:00
Who are you?
- Your name?
- Your preferred pronouns?
- Your research?
- Your mood on a sheep scale?

Pair Programming (variant)
- Find and say hello to your nearest desk neighbor
- Complete the exercises together, help each other out, etc.

Let’s do the splits

Definition of reproducibility
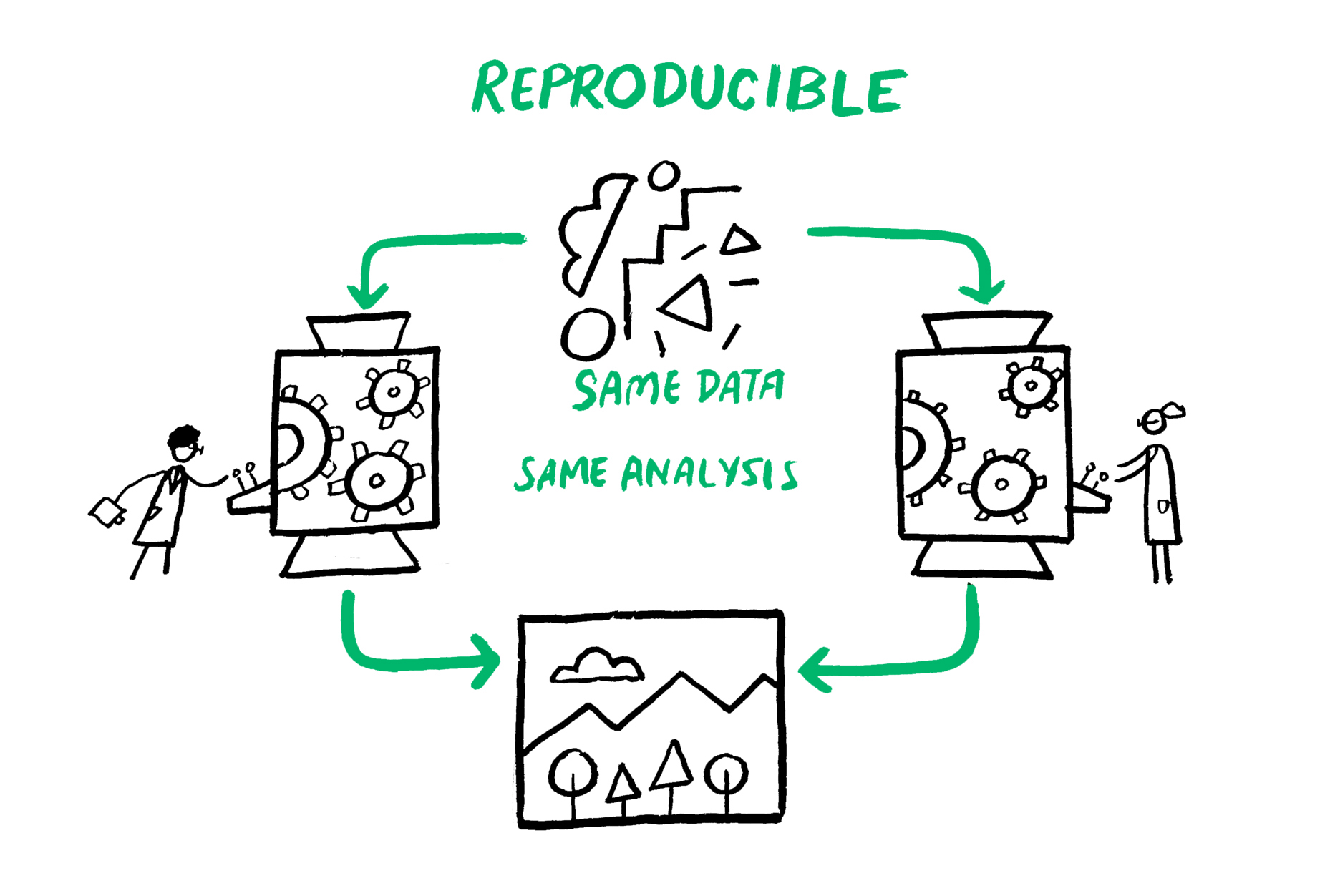
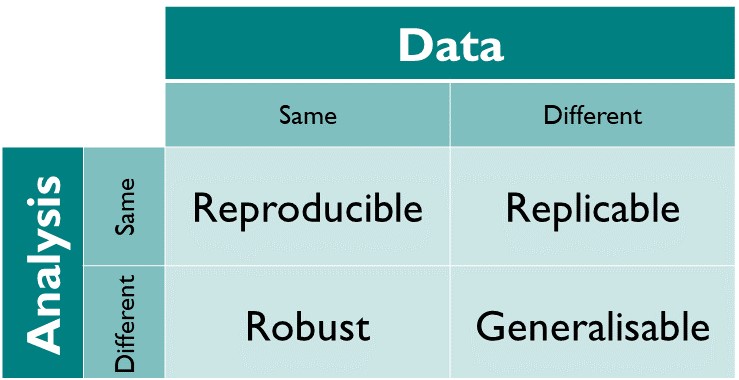
The issue of computational reproducibility in science
The problem
- about more than half of research is not reproducible 3
- research data, code, software & materials are often not available “upon reasonable [sic] request”
- if resources are shared, they are often incomplete
- 90% of researchers: “reproducibility crisis” (N = 1576) 4
Why?
- computational reproducibility is hard
- researchers lack training
- incentives are not (yet) aligned 5
- more …
“… accumulated evidence indicates […] substantial room for improvement with regard to research practices to maximize the efficiency of the research community’s use of the public’s financial investment.” (Munafò et al., 2017)
We need a professional toolkit for digital research!
What about Open Science?
Open science is an umbrella term for activities that aim to promote open approaches to science and research.
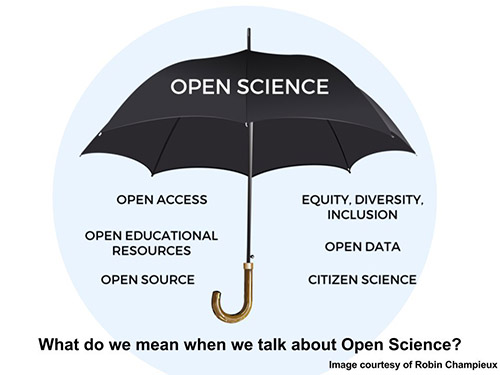
Note: Research can be reproducible but not open
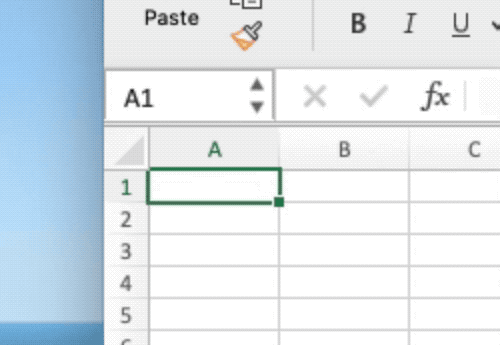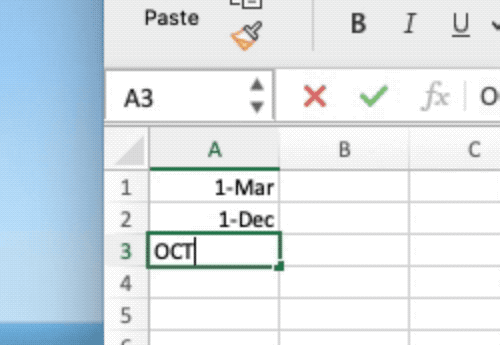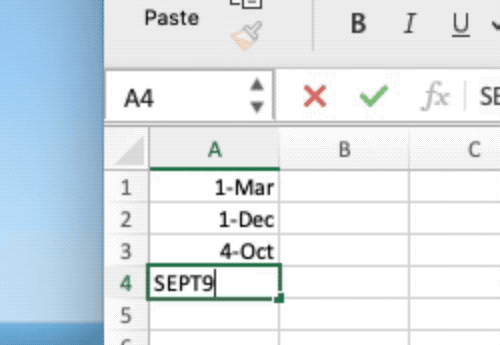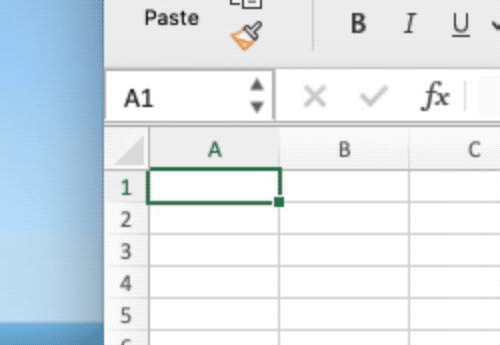
Excel: A cautionary tale
Try this exercise:
- Open an Excel Sheet.
- Set first column to date-format.
- Enter the year 2010 into cell A1.
Result: Excel renders your entry as 2nd July 1905!
More seriously …
- Common gene symbols:
SEPT2,MARCH1, etc. - ~20% of genetic research affected by Excel errors (Ziemann et al., 2016)
- “Solution”: HUGO Gene Nomenclature Committee renamed genes!
Why is Excel still used?
- Very intuitive
- Easy data entry
- Built-in functions
- Quick to work with
Recommendation
- Use Excel for data entry only
- Use or Python for analysis
- Save computations in scripts for reproducibility
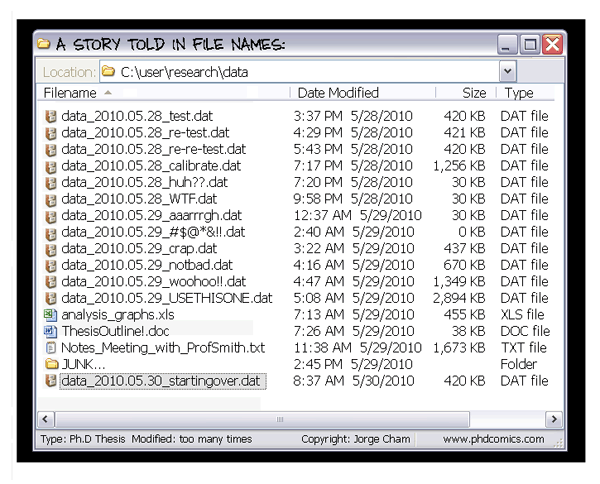
Let’s avoid this
FAIR principles
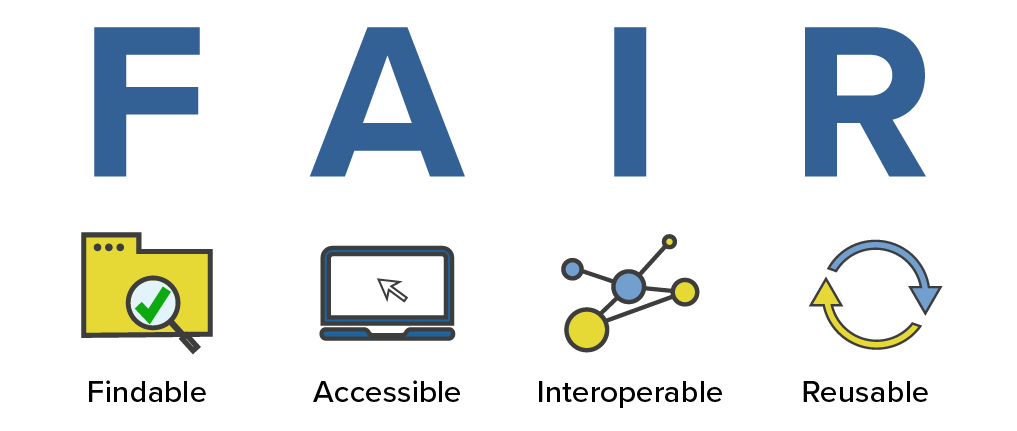
FAIR stands for Findable, Accessible, Interoperable, and Reusable (Wilkinson et al., 2016)
Benefits:
- Enhanced machine readability
- Improved human readability
- Better findability
- Long-term accessibility
Key concepts for reproducibility:
- Persistent identifiers (DOIs)
- Metadata (data about your data)
Data organization & standards
Questions to ask yourself:
- What data are you working with?
- Which analysis pipelines are you using?
- Is there a community standard?
Why use community standards?
- Facilitate cooperation between labs
- Ensure consistency within your lab
- Make reproducibility easier
- Enhance data sharing

Data organization includes:
- Folder structure and naming
- File format choices
- Metadata documentation
- Consistent approaches
More challenges for reproducible scientific workflows
Version Control

{kind=link}
Computational Environments

Footnotes
The Turing Way Community (2022), see “Guide on Reproducible Research”
The Turing Way Community (2022), see “Guide on Reproducible Research”
for example, in Psychology: Crüwell et al. (2023); Hardwicke et al. (2021); Obels et al. (2020); Wicherts et al. (2006)
see Baker (2016), Nature
see e.g., Poldrack (2019)
“Data Sharing and Management Snafu in 3 Short Acts”. The video by Hanson et al. (2019) from NYU Health Sciences Library features a cute animated panda researcher making a data sharing request to a bear researcher. It does not go well. The video aims to communicate some of the common and avoidable pitfalls of research data management in a light-hearted format. Topics include storage, documentation, and file formats. The video was produced using a tool called Xtranormal (now “nawmal”) and the characters are strangely expressive while talking in robotic text-to-speech voices with a limited range of movement. It was created and uploaded to YouTube by librarians at NYU School of Medicine in 2012 to be used for research data management education and has been included in numerous research data management courses and presentations. License: Creative Commons Attribution 4.0 International (CC BY 4.0). Reused without modifications.