Reproducible Research Data Management with DataLad
6th RDM-Workshop 2024 on Research Data Management in the Max Planck Society
![]()
![]()

March 20, 2024
About

Dr. Lennart Wittkuhn
wittkuhn@mpib-berlin.mpg.de
https://lennartwittkuhn.com/
Mastodon GitHub LinkedIn
About me
I am a Postdoctoral Research Data Scientist in Cognitive Neuroscience at the Institute of Psychology at the University of Hamburg (PI: Nicolas Schuck)
BSc Psychology & MSc Cognitive Neuroscience (TU Dresden), PhD Cognitive Neuroscience (Max Planck Institute for Human Development)
I study the role of fast neural memory reactivation in the human brain, applying machine learning and computational modeling to fMRI data
I am passionate about computational reproducibility, research data management, open science and tools that improve the scientific workflow
Find out more about my work on my website, Google Scholar and ORCiD
About this presentation
Slides: https://lennartwittkuhn.com/talk-mps-fdm-2024
Source: https://github.com/lnnrtwttkhn/talk-mps-fdm-2024
Software: Reproducible slides built with Quarto and deployed to GitHub Pages using GitHub Actions for continuous integration & deployment
License: Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA 4.0)
Contact: Feedback or suggestions via email or GitHub issues. Thank you!
Acknowledgements and further reading

Slides and presentations by Dr. Adina Wagner and the DataLad team, e.g., “DataLad - Decentralized Management of Digital Objects for Open Science” (Wagner 2024)
The DataLad Handbook by Wagner et al. (2022) is a comprehensive educational resource for data management with DataLad.
Papers
- Wilson et al. (2014). Best practices for scientific computing. PLOS Biology.
- Wilson et al. (2017). Good enough practices in scientific computing. PLOS Computational Biology.
- Lowndes et al. (2017). Our path to better science in less time using open data science tools. Nature Ecology Evolution.
Talks
- Richard McElreath (2020). Science as amateur software development. YouTube
- Russ Poldrack (2020). Toward a Culture of Computational Reproducibility. YouTube
… and many more!
Why we need version control
… for code (text files) 

… for data (binary files) 
If everything is relevant, track everything.
What is version control?
“Version control is a systematic approach to record changes made in a […] set of files, over time. This allows you and your collaborators to track the history, see what changed, and recall specific versions later […]” (Turing Way)
keep track of changes in a directory (a “repository”)
take snapshots (“commits”) of your repo at any time
know the history: what was changed when by whom
compare commits and go back to any previous state
work on parallel “branches” & flexibly “merge” them

“push” your repo to a “remote” location & share it
share repos on platforms like GitHub or GitLab
work together on the same files at the same time
others can read, copy, edit and suggest changes
make your repo public and openly share your work

What are Git and DataLad?
![]()
- most popular version control system
- free, open-source command-line tool
- graphical user interfaces exist, e.g., GitKraken
- standard tool in the software industry
- 100 million GitHub users 1
Sadly, Git does not handle large files well.
![]()
- “Git for (large) data”
- free, open-source command-line tool
- builds on top of Git and git-annex
- allows to version control arbitrarily large datasets 2
- DataLad Python API: Use DataLad in your Python code
- graphical user interface exists: DataLad Gooey

Example Dataset: Brain Imaging Data
Single subject epoch (block) auditory fMRI activation data
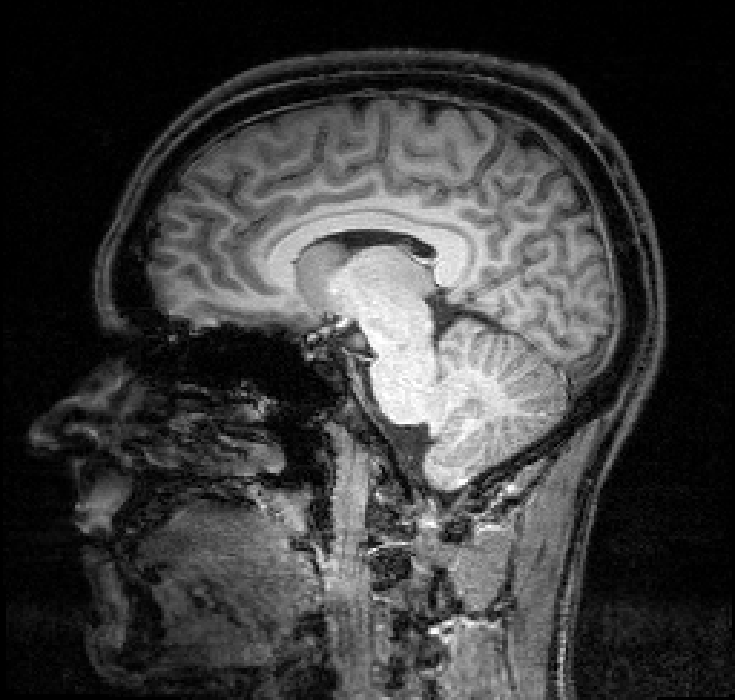
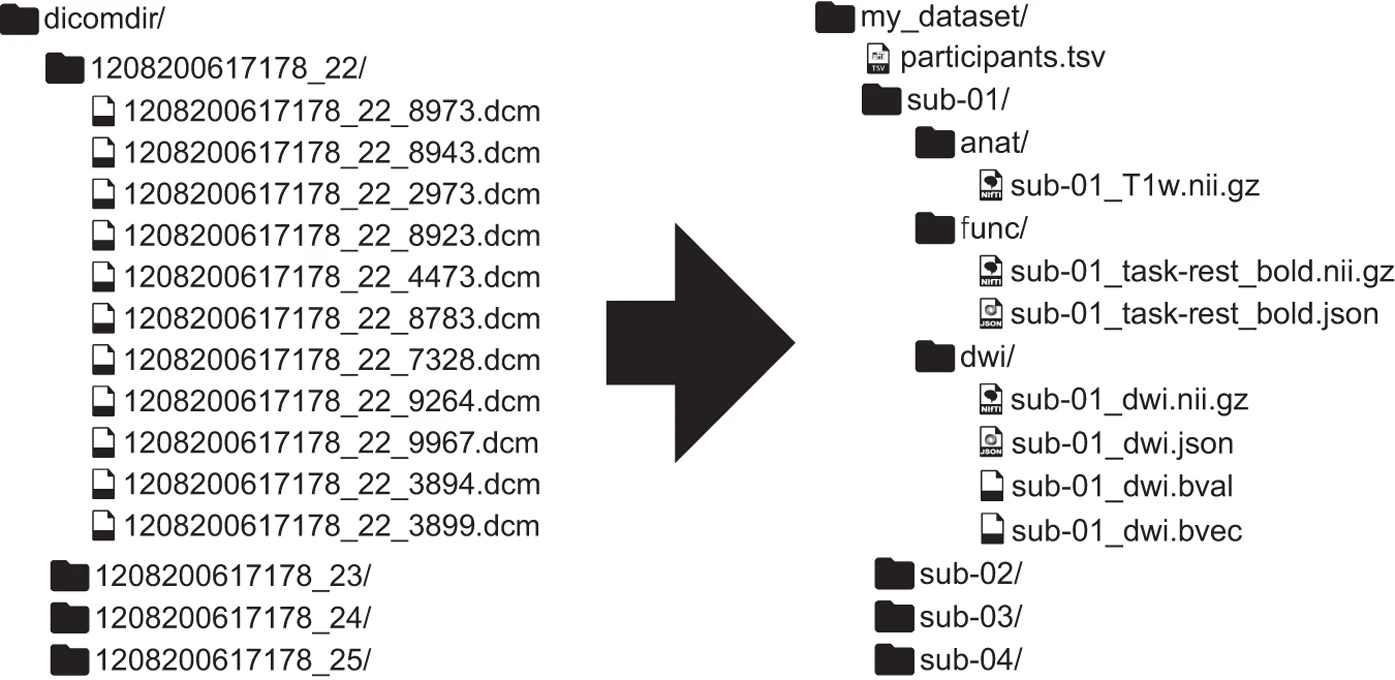
Dataset from Functional Imaging Laboratory, UCL Queen Square Institute of Neurology, London, UK (Source)
Version Control with DataLad


View output
add(ok): CHANGES (file)
add(ok): README (file)
add(ok): dataset_description.json (file)
add(ok): sub-01/anat/sub-01_T1w.nii (file)
add(ok): sub-01/func/sub-01_task-auditory_bold.nii (file)
add(ok): sub-01/func/sub-01_task-auditory_events.tsv (file)
add(ok): task-auditory_bold.json (file)
save(ok): . (dataset) action summary:
add (ok: 7)
save (ok: 1)Data in DataLad datasets are either stored in Git or git-annex

Git
- handles small files well (text, code)
- file contents are in Git history and will be shared
- Shared with every dataset clone
- Useful: small, non-binary, frequently modified files
git-annex
- handles all types and sizes of files well
- file contents are in the annex, not necessarily shared
- Can be kept private on a per-file level
- Useful: Large files, private files
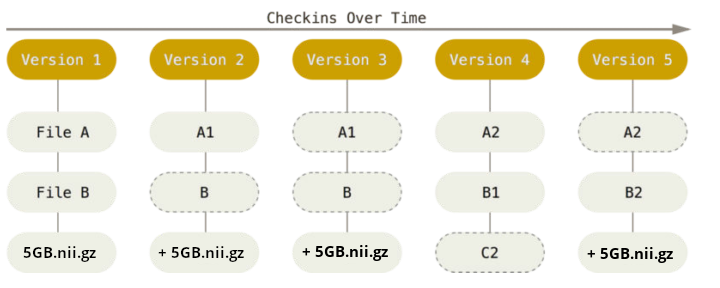
Version control beyond single repositories
Research as a sequence

- Prior works (code development, empirical data, etc.) are combined to produce results with goal of a publication
- Aggregation across time and contributors
- Aiming for (but often failing) to be reproducible
- Often, there is one big project folder
A single repository is not enough!

Nesting of modular DataLad datasets

- seamless nesting of modular datasets in hierarchical super-/sub-dataset relationships
- based in Git submodules, but mono-repo feel thanks to recursive operations
- overcomes scaling issues with large amounts of files (Example: Human Connectome Project)
- modularizes research components for transparency, reuse and access management
Example: Intuitive data analysis structure
First, let’s create a new data analysis dataset:
datalad create -c yoda myanalysis
[INFO ] Creating a new annex repo at /tmp/myanalysis
[INFO ] Scanning for unlocked files (this may take some time)
[INFO ] Running procedure cfg_yoda
[INFO ] == Command start (output follows) =====
[INFO ] == Command exit (modification check follows) =====
create(ok): /tmp/myanalysis (dataset)-c yoda initializes useful structure (details here):
We install analysis input data as a subdataset to the dataset:
datalad clone -d . https://github.com/datalad-handbook/iris_data.git input/
[INFO ] Remote origin not usable by git-annex; setting annex-ignore
install(ok): input (dataset)
add(ok): input (dataset)
add(ok): .gitmodules (file)
save(ok): . (dataset)
action summary:
add (ok: 2)
install (ok: 1)
save (ok: 1)Modular units with clear provenance
git diff HEAD~1
diff --git a/.gitmodules b/.gitmodules
new file mode 100644
index 0000000..fc69c84
--- /dev/null
+++ b/.gitmodules
@@ -0,0 +1,5 @@
+[submodule "input"]
+ path = input
+ url = https://github.com/datalad-handbook/iris_data.git
+ datalad-id = 5800e71c-09f9-11ea-98f1-e86a64c8054c
+ datalad-url = https://github.com/datalad-handbook/iris_data.git
diff --git a/input b/input
new file mode 160000
index 0000000..b9eb768
--- /dev/null
+++ b/input
@@ -0,0 +1 @@
+Subproject commit b9eb768c145e4a253d619d2c8285e540869d2021

Reusing previous work is hard


Establishing provenance with DataLad
datalad run wraps around anything expressed in a command line call and saves the dataset modifications resulting from the execution.
datalad rerun repeats captured executions. If the outcomes differ, it saves a new state of them.
datalad containers-run executes command line calls inside a tracked software container and saves the dataset modifications resulting from the execution.
datalad containers-run \
--message "Time series extraction from Locus Coeruleus"
--container-name nilearn \
--input 'mri/*_bold.nii' \
--output 'sub-*/LC_timeseries_run-*.csv' \
"python3 code/extract_lc_timeseries.py"
-- Git commit --
commit 5a7565a640ff6de67e07292a26bf272f1ee4b00e
Author: Adina Wagner adina.wagner@t-online.de
AuthorDate: Mon Nov 11 16:15:08 2019 +0100
[DATALAD RUNCMD] Time series extraction from Locus Coeruleus
=== Do not change lines below ===
{
"cmd": "singularity exec --bind {pwd} .datalad/environments/nilearn.simg bash..",
"dsid": "92ea1faa-632a-11e8-af29-a0369f7c647e",
"inputs": [
"mri/*.bold.nii.gz",
".datalad/environments/nilearn.simg"
],
"outputs": ["sub-*/LC_timeseries_run-*.csv"],
...
}
^^^ Do not change lines above ^^^
- Enshrine the analysis in a script and record code execution together with input data, output files and software environment in the execution command
- Result: Machine readable record about which data, code and software produced a result how, when and why
- Use the unique identifier (hash) of the execution record to have a machine recompute and verify past work
datalad rerun 5a7565a640ff6de67
[INFO ] run commit 5a7565a640ff6de67; (Time series extraction from Locus Coeruleus)
[INFO ] Making sure inputs are available (this may take some time)
get(ok): mri/sub-01_bold.nii (file)
[...]
[INFO ] == Command start (output follows) =====
[INFO ] == Command exit (modification check follows) =====
add(ok): sub-01/LC_timeseries_run-*.csv(file)Data sharing and collaboration with DataLad
“I have a dataset on my computer.
How can I share it or collaborate on it?”

Challenge: Scientific workflows are idiosyncratic across institutions / departments / labs / any two scientists
Share data like code
- With DataLad, you can share data like you share code: As version-controlled datasets via repository hosting services
- DataLad datasets can be cloned, pushed and updated from and to a wide range of remote hosting services

Interoperability with a range of hosting services
DataLad is built to maximize interoperability and streamline routines across hosting services and storage technology
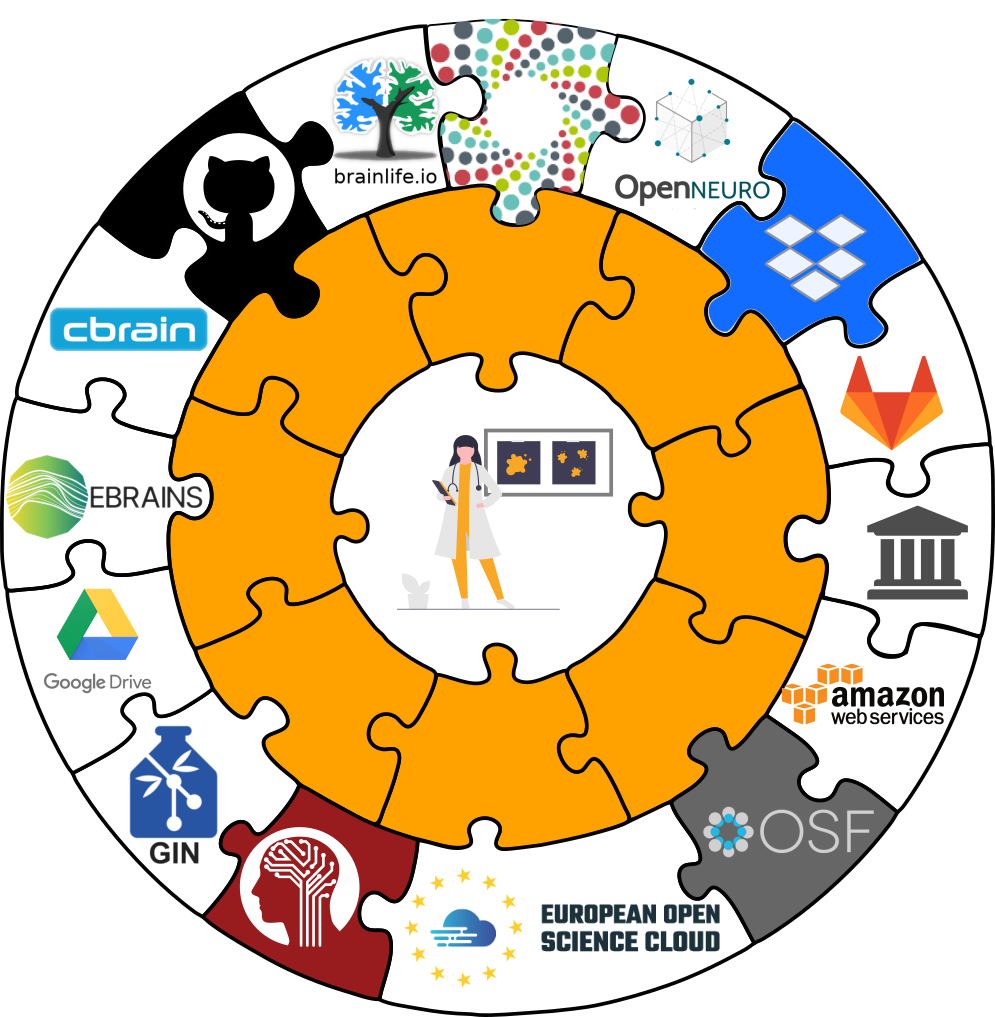
Separate content in Git vs. git-annex behind the scenes
- DataLad datasets are exposed via private or public repositories on a repository hosting service (e.g., GitLab or GitHub)
- Data can’t be stored in the repository hosting service but can be kept in almost any third party storage
- Publication dependencies automate interactions between both paces

Special cases
Repositories with annex support

- Easy: Only one remote repository
- Examples: GIN, GitLab with annex support
Special remotes with repositories

- Flexible: Full history or single snapshot
- Examples: DataLad-OSF
Sharing DataLad datasets via Keeper
“A free service for all Max Planck employees and project partners with more than 1TB of storage per user for your researchdata.”
✨ Features of Keeper ✨
- > 1 TB per Max Planck employee (and expandable):
- based on cloud-sharing service Seafile
- data hosted on MPS servers
- configurable as a DataLad special remote
Sharing DataLad datasets via Edmond
“Edmond is a research data repository for Max Planck researchers. It is the place to store completed datasets of research data with open access.”
✨ Features of Edmond ✨
- based on Dataverse, hosted on MPS servers
- use is free of charge
- no storage limitation (on datasets or individual files)
- flexible licensing
Two modes:
annex mode (default): non-human readable representation of the dataset that includes Git history and annexed data
filetree mode: human readable single snapshot of your dataset “as it currently is” that does not include history of annexed files (but Git history)
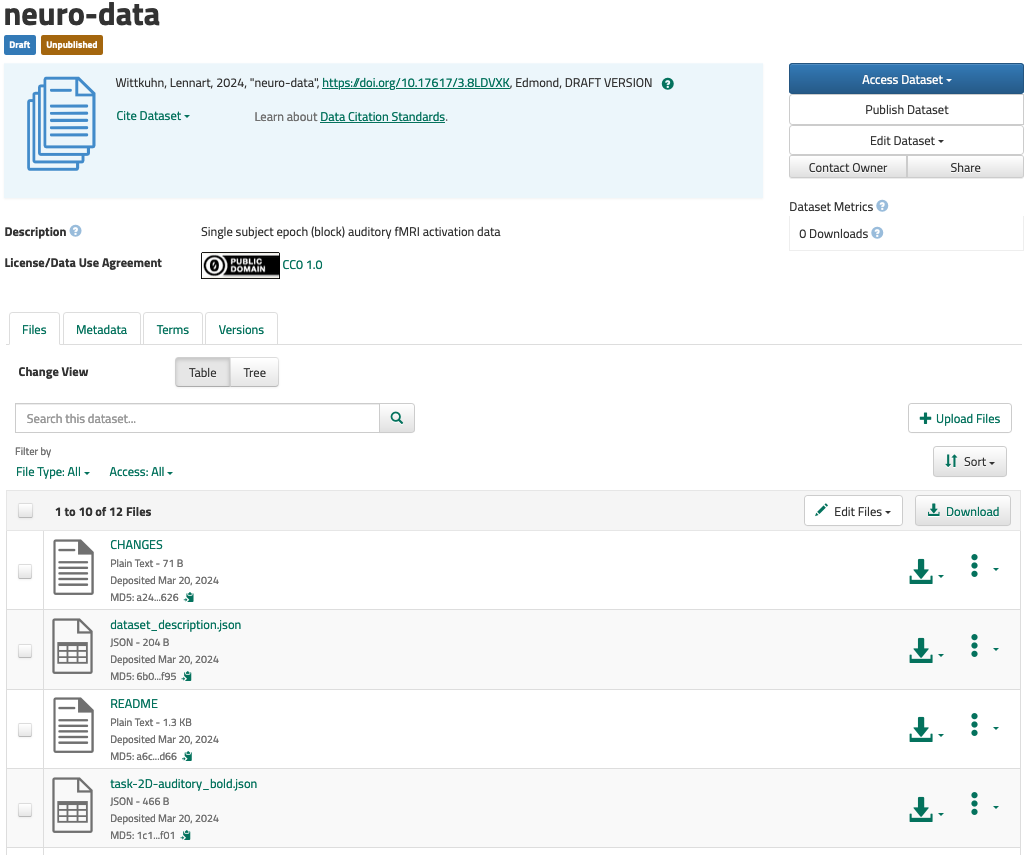
Sharing DataLad datasets via ownCloud / Nextcloud
DataLad NEXT extension allows to push / clone DataLad datasets to / from ownCloud & Nextcloud (via WebDAV)
ownCloud GWDG: “50 GByte default storage space per user; flexible increase possible upon request”
✨ Features of ownCloud and Nextcloud ✨
- data privacy compliant alternative to Google Drive, Dropbox, etc. (usually hosted on-site)
- provided by your institution, so free to use
- supports private and public repositories
- can be used together with external collaborators
- expose datasets for regular download without DataLad
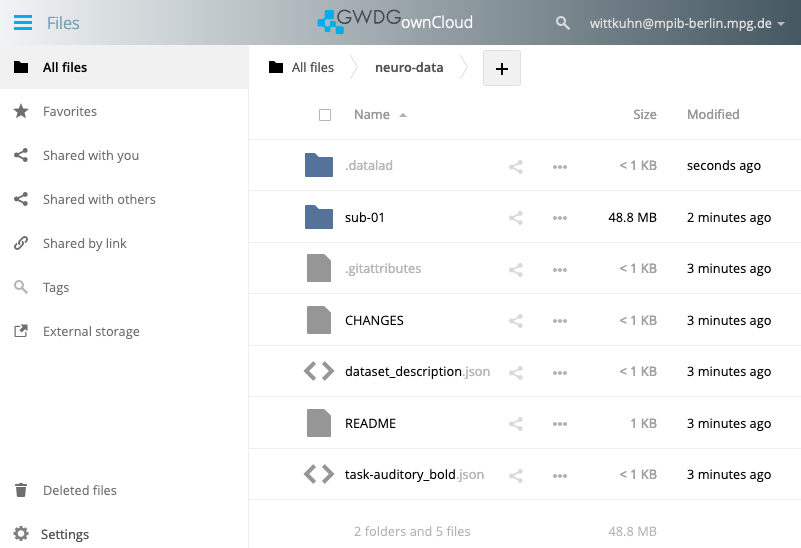
Sharing DataLad datasets via GIN
“GIN is […] a web-accessible repository store of your data based on git and git-annex that you can access securely anywhere you desire while keeping your data in sync, backed up and easily accessible […]“
✨ Features of GIN ✨
- free to use and open-source (could be hosted within your institution; for more details, see here)
- currently unlimited storage capacity and no restrictions on individual file size
- supports private and public repositories
- publicly funded by the Federal Ministry of Education and Research (BMBF; details here)
- servers on German land (Munich, Germany; cf. GDPR)
- provides Digital Object Identifiers (DOIs) (details here) and allows free licensing (details here)
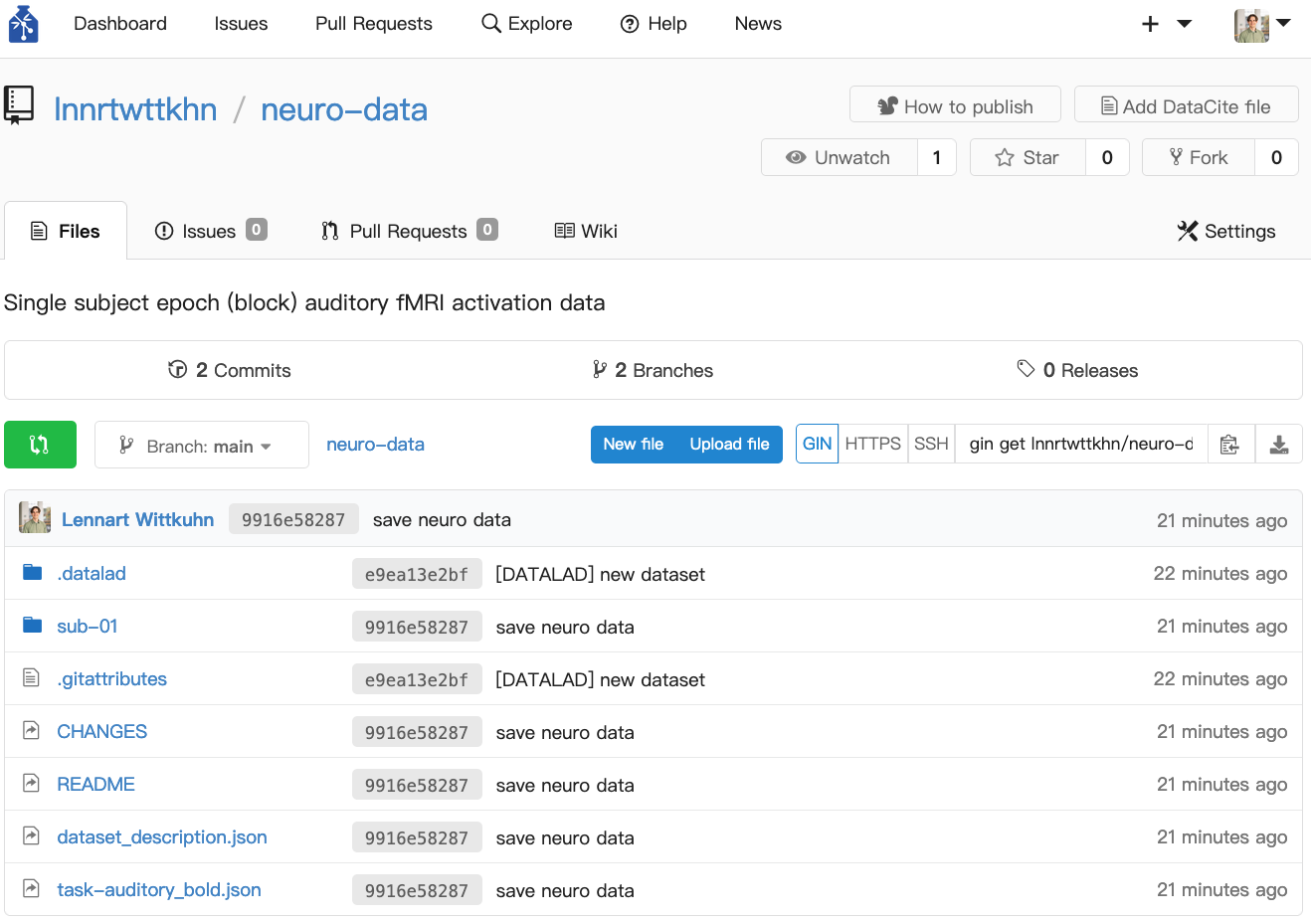
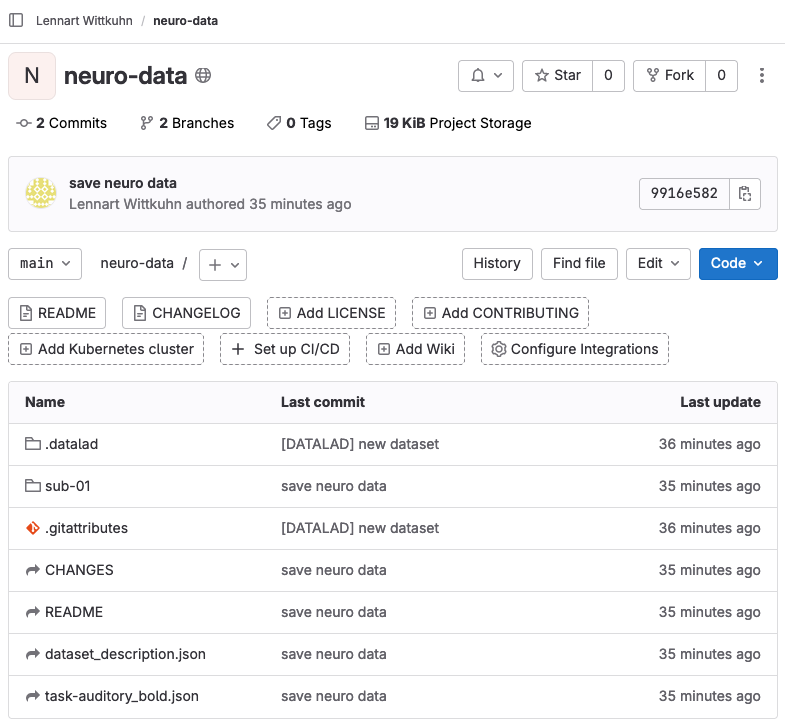
Sharing DataLad datasets via GitLab
“GitLab is open source software to collaborate on code. Manage git repositories with fine-grained access controls that keep your code secure.”
GitLab for Max Planck employees
- hosted by GWDG: gitlab.gwdg.de
- hosted by your institute, e.g., git.mpib-berlin.mpg.de
✨ Features of GitLab ✨
- free to use and open-source
- several MPS instances available (see above)
- supports private and public repositories
- use project management infrastructure (merge requests, issue boards, etc.) for your dataset projects
{kind=link}
{kind=link}
Publish and consume datasets like source code
Datasets can comfortably live in multiple locations:
Publication dependencies automate update in all places:

Redundancy: DataLad gets data from available sources
Clone the dataset from GitLab:
Access to special remotes needs to be configured:
DataLad retrieves data from available sources (here, GIN):
Thank you!
Dr. Lennart Wittkuhn
wittkuhn@mpib-berlin.mpg.de
https://lennartwittkuhn.com/
Mastodon GitHub LinkedIn
![]()
![]()
![]()
![]()
![]()
![]()
Slides: https://lennartwittkuhn.com/talk-mps-fdm-2024
Source: https://github.com/lnnrtwttkhn/talk-mps-fdm-2024
Software: Reproducible slides built with Quarto and deployed to GitHub Pages using GitHub Actions for continuous integration & deployment
License: Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA 4.0)
Contact: Feedback or suggestions via email or GitHub issues. Thank you!
Footnotes
(Source: Wikipedia)
see DataLad dataset of 80TB / 15 million files from the Human Connectome Project (see details)
Dataverse datasets contain digital files (research data, code, …), amended with additional metadata. They typically live inside of dataverse collections.
At least,
Title,Description, andOrganizationare required.