
| No | Time | Title | Contents |
|---|---|---|---|
| 1 | 09:30 - 10:00 | Introduction to Version Control | Logistics and course admin Introduction to reproducibility Introduction to version control Introduction to Git |
| 2 | 10:00 - 10:45 | Basics of the Command Line | File systems and navigation Benefits of the command line Basic command line commands |
| 3 | 10:45 - 11:00 | Setup & configuration of Git | Setup & configuration of Git |
| 4 | 11:00 - 12:00 | Basics of Git | Initializing a Git repository Practicing basic Git commands Tracking changes wih Git Ignoring files with .gitignoreGood commit messages |
| 5 | 12:00 - 13:00 | Lunch Break | Enjoy your lunch! |
| 6 | 13:00 - 14:00 | Integration with GitHub / GitLab | Introduction to remote repositories Managing repositories on GitHub / GitLab Pushing and pulling changes Cloning a remote repository |
| 7 | 14:00 - 15:00 | Version Control of Data with DataLad | Version control of (large) data with DataLad Nesting modular datasets with DataLad Establishing provenance and reproducibility with DataLad |
| 8 | 16:00 - 16:30 | Summary & Outlook | Summary of course contents Outlook to more related topics Discussing open questions |
Session 8: Summary & Outlook
Track, organize and share your work: Version control of code & data with Git & DataLad
Course at AUDICTIVE Priority Program
![]()
![]()
16:00
How are you now?

Rewriting history
See chapter “Rewriting History”

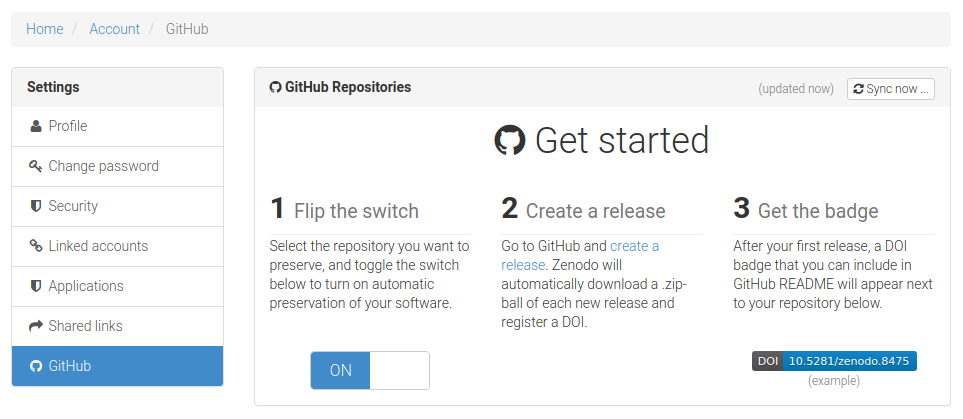
Tags, releases, DOIs: Integration with Zenodo
“Zenodo, a CERN service, is an open dependable home for the long-tail of science, enabling researchers to share and preserve any research outputs in any size, any format and from any science.” – from the Zenodo GitHub README

Integrate your repository on GitHub with Zenodo
“To make your repositories easier to reference in academic literature, you can create persistent identifiers, also known as Digital Object Identifiers (DOIs). You can use the data archiving tool Zenodo to archive a repository on GitHub.com and issue a DOI for the archive.” – Details in the GitHub documentation
- Navigate to the login page for Zenodo.
- Click Log in with GitHub.
- Review the information about access permissions, then click Authorize zenodo.
- Navigate to the Zenodo GitHub page.
- To the right of the name of the repository you want to archive, toggle the button to On.
See our book chapter on “Tags & Releases”.
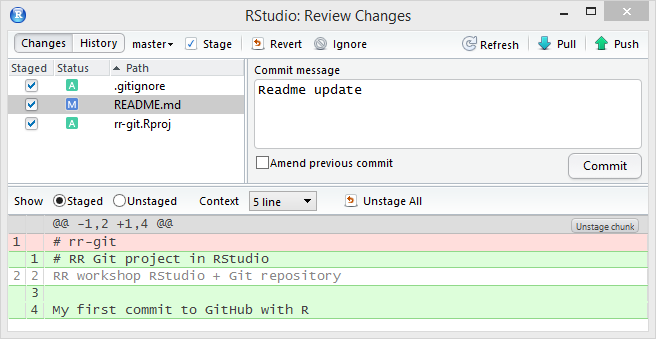
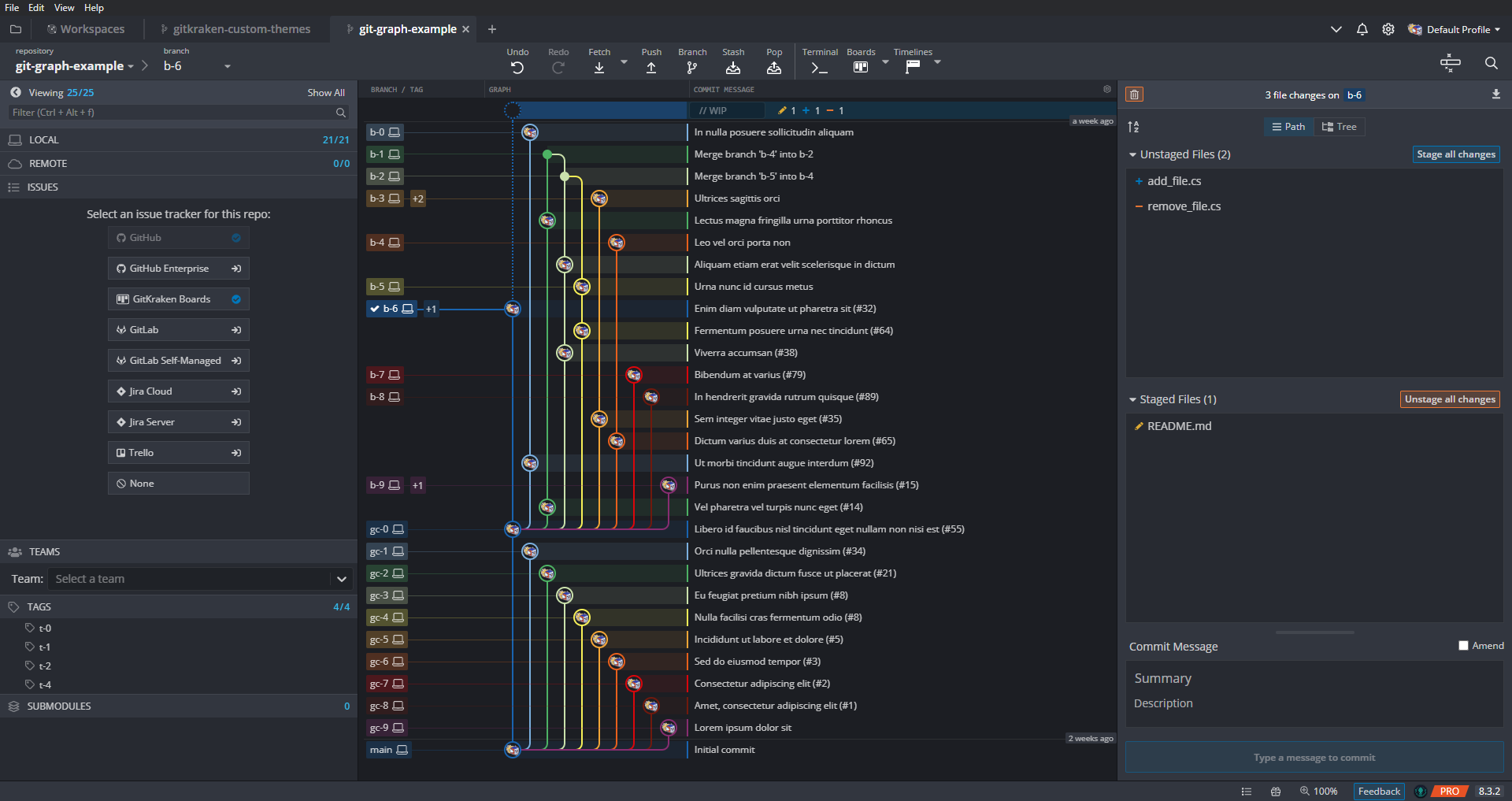
Graphical User Interfaces (GUIs) for Git
Integrated Development Environments (IDEs)
RStudio
MATLAB
Git Clients
GitKraken
GitHub Desktop
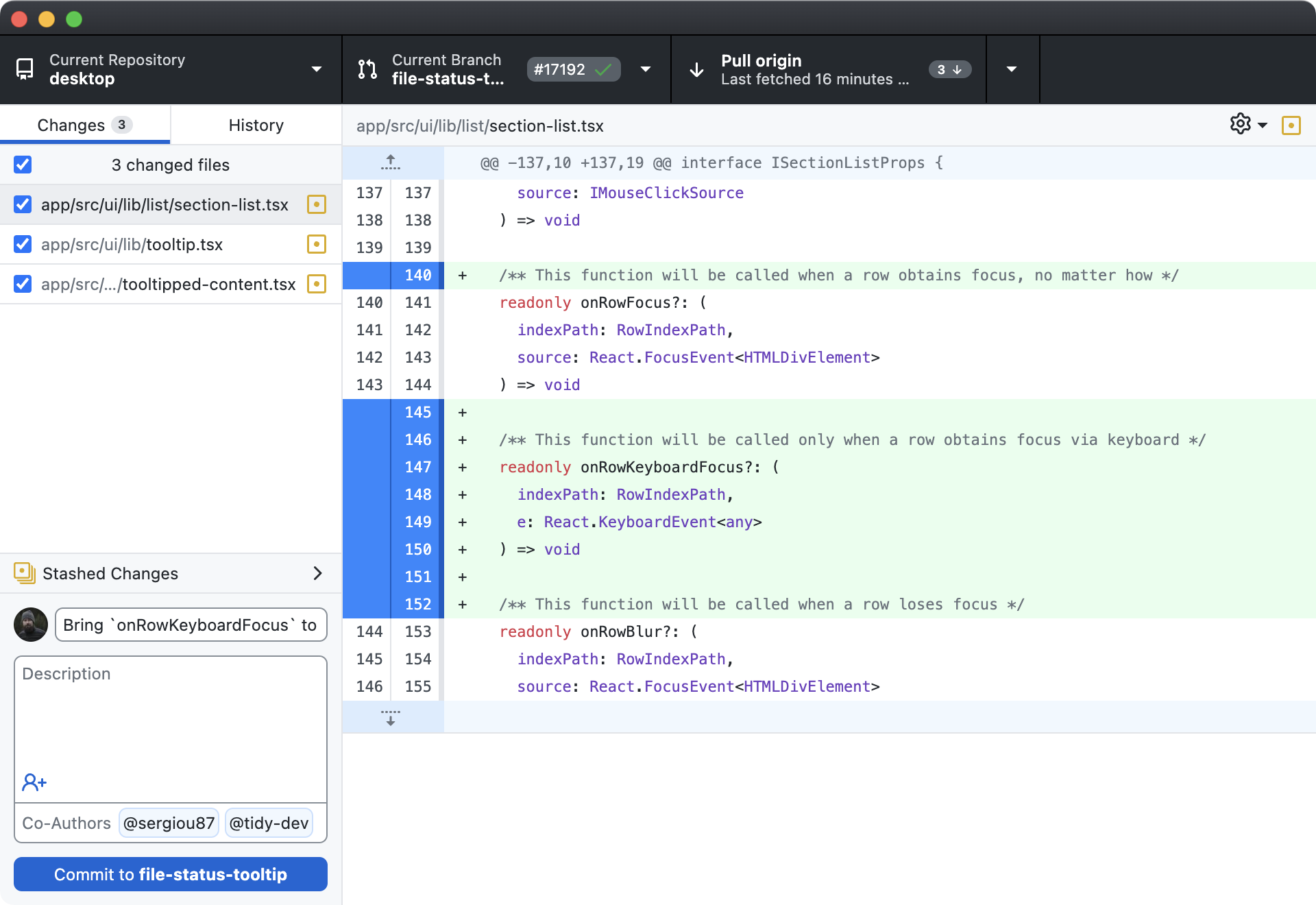
Mobile
Working Copy (iOS)
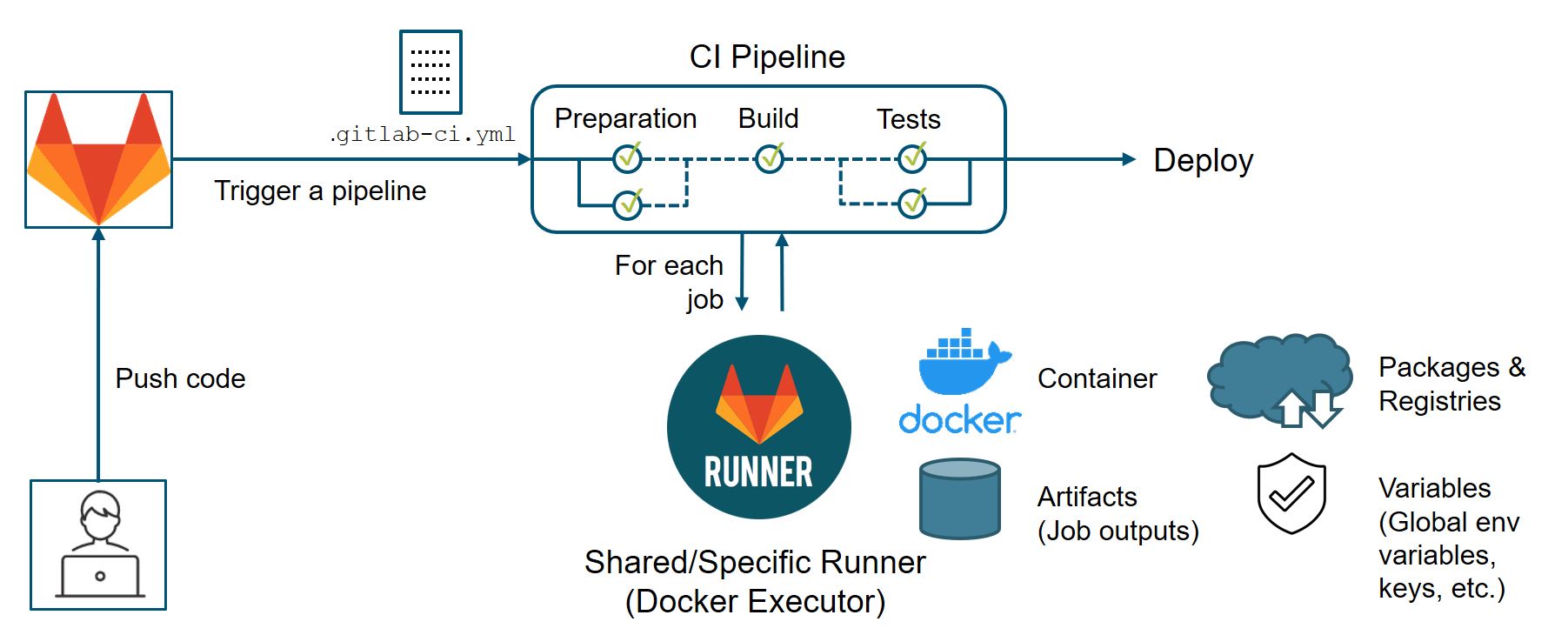
Continuous Integration & Deployment (CI/CD)
Example: Lennart’s recipes repo
- Automated spell check
- Rebuilding of project website
Science as distributed open-source knowledge development 1
How can we do better science?
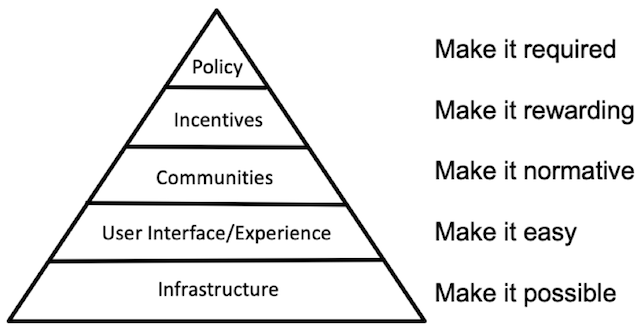
The long-term challenges are non-technical
- open-source, avoiding commercial vendor lock-in
- adopting new practices and upgrading workflows
- moving towards a “culture of reproducibility” 2
- changing incentives, policies & funding schemes
Technical solutions already exist!
- Version control of digital research outputs (e.g., Git, DataLad)
- Integration with flexible infrastructure (e.g., GitLab)
- Systematic contributions & review (e.g., pull/merge requests)
- Automated integration & deployment (e.g., CI/CD)
- Reproducible computational environments (e.g., Docker)
- Transparent execution and build systems (e.g., GNU Make)
- Project communication next to code & data (e.g., Issues)
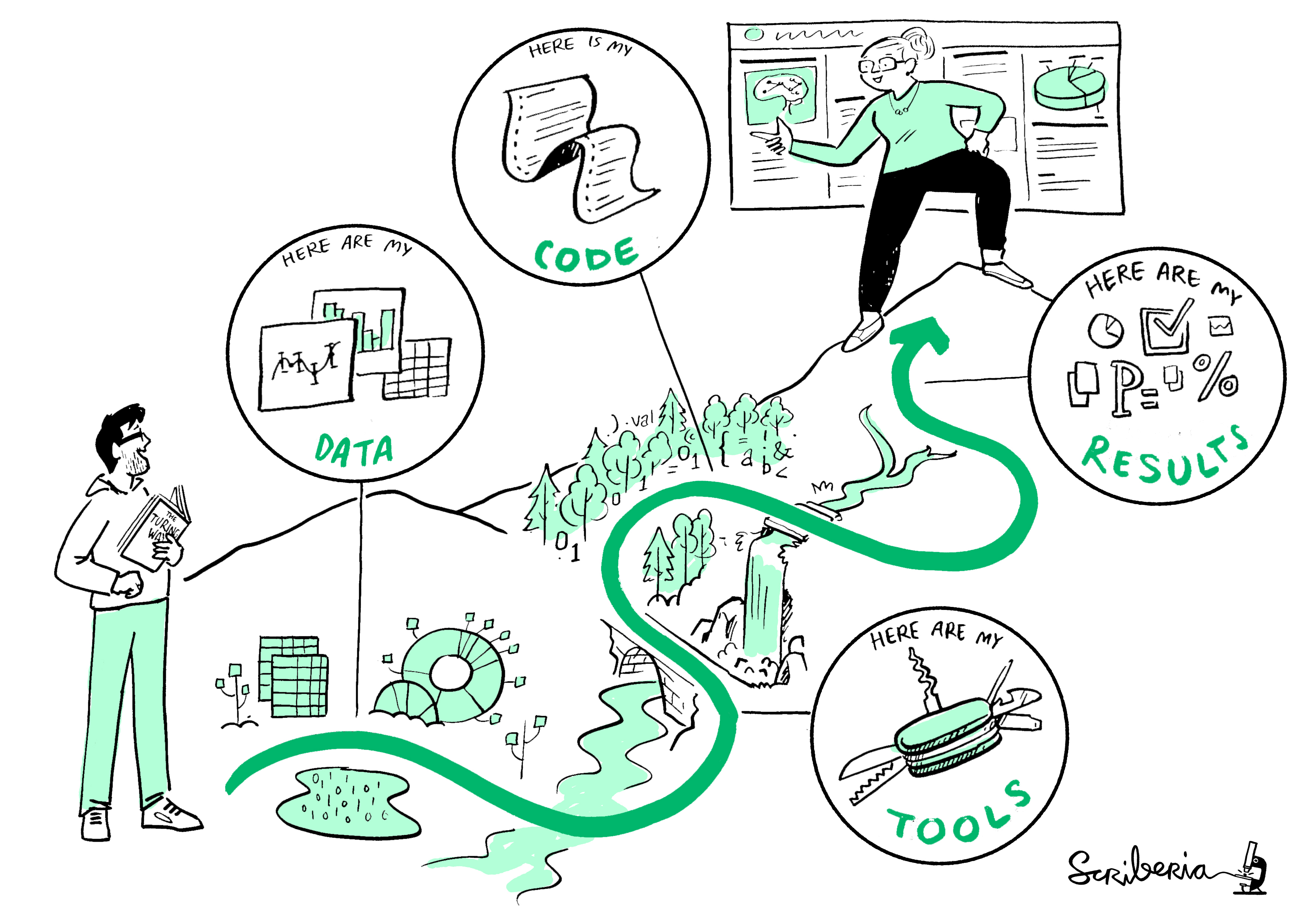
Reproducibility is a spectrum and a journey

Footnotes
inspired by Richard McElreath’s “Science as Amateur Software Development” (2023)
see “Towards a culture of computational reproducibility” by Russ Poldrack, Stanford University