In this chapter you will learn how to name things. You get to know different principles for naming files and folders and accompanying tips how to apply them.
Learning Objectives
💡 You know different principles to name things. 💡 You know what regular expressions and globbing are. 💡 You know what a file name should contain to be easily processed by a computer. 💡 You know what a file name should contain to be easily understood by a human being. 💡 You know how to consistently name files. 💡 You know how to use date formats and numbering. 💡 You know how to use hyphens and underscores when naming files.
3.1 Examples
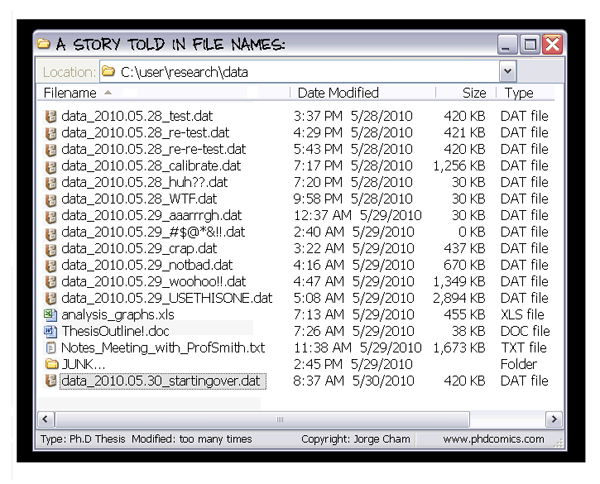
Reflect on your first research project (or perhaps your most recent project). Take a moment to look at all the files you needed for that project. Can you determine what they contain just by their names? Below, you will find a real-life example from a second-semester undergraduate student in psychology. Which files would you want to encounter when you start reproducing results?
CautionExercise: What is bad or good about these file names?
Pause for a moment and think about what exactly makes the file names above bad or better? Discuss with a learning partner.
“There are only two hard things in Computer Science: cache invalidation and naming things.” – Phil Karlton
In research, naming things can often be more difficult than it seems. Whether you’re giving names to variables in a dataset, labeling files for your projects, or creating functions in a script, the names you choose are important for making your work clear and understandable. Good names help others (and yourself!) know what your work is about and how to use it.
Finding the right names takes careful thought. You need to consider what makes sense in context and how to be clear and consistent. This chapter will look at some common challenges people face when naming things in research and provide simple tips to improve your naming practices. By understanding these challenges, you can make your research easier to follow and more accessible to others and avoid situations as illustrated in Figure 3.1.
NoteOk, what the heck is cache invalidation and why is it hard?
Cache invalidation is the process of updating or removing old data stored in a cache (a temporary storage area) when the original data changes. Caches are used to speed up access to frequently used data, but if the cache isn’t updated correctly, it may end up providing outdated or incorrect information. It is challenging for several reasons: first, determining the right moment to update the cache can be difficult, risking the delivery of outdated information. Additionally, many data pieces are interconnected, making it hard to track what needs updating when changes occur. Lastly, automatically updating caches can slow down systems, so finding a balance between performance and accuracy is tricky. These complexities make effective cache invalidation one of the most difficult problems in software development.
3.3 Principles for (file) names
Good file naming practices are essential for organization, clarity, and efficient file management. Here are some key principles to follow when creating file names:
A file is machine-readable if information is formatted in a way that a computer can easily read and understand it without needing a human to interpret or manually enter the data. This often involves using standardized data formats like CSV, XML, or JSON, which are structured so that computer programs can process the information quickly and accurately. There are two main concepts that help computers quickly search and match patterns in text or file names, making data processing tasks easier and faster: regular expressions and globbing.
3.4.1 Regular expression and globbing friendly
Both regular expression and globbing are concepts that help make working with files and data more efficient for automation and scripting tasks.
A regular expression, often called a “regex”, is a sequence of characters that defines a search pattern. It’s used to find or match specific combinations of characters within text. You can think of it as a tool for searching text in a very precise and flexible way.
Globbing is a way to use special characters (called “wildcards”) to match multiple files or directories in command-line interfaces or scripts. It helps you to select groups of files without typing every single name.
Common wildcards in globbing:
* (asterisk): Matches any number of characters. For example, *.txt matches all files ending with .txt.
? (question mark): Matches exactly one character. For example, file?.txt matches file1.txt and file2.txt, but not file10.txt.
So, if you wanted to list all text files in a directory, you could use the pattern *.txt, and it would match all files with the .txt extension.
3.4.2 How to make files regex and globbing friendy
To make file names regex and globbing friendly, avoid:
spaces
punctuation
accented characters
case sensitivity
NoteWhat are regular expressions?
A regular expression is a special sequence of characters that helps you to search for patterns in text. It allows you to find specific words or phrases within a larger body of text. For example, imagine you have a text document and you want to find all email addresses mentioned in it. You can use the following regular expression to search for email addresses:
This pattern will match any text that looks like an email address, such as example@email.com. Imagine that you have a text like the following:
Please contact me at john.doe@email.com for any inquiries. You can also reach out to jane.smith@example.com for more information.
You can see regular expression in action with this example:
Code
echo"Please contact me at john.doe@email.com for any inquiries. You can also reach out to jane.smith@example.com for more information."|grep-Eo"\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b"
Here is what happens with this command:
echo is used to display the sample text.
The pipe (|) sends the output of echo as input to grep.
grep -Eo enables extended regular expressions and prints only the matching part of the line.
The regular expression \b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b is used to identify email addresses in the text output by echo.
You can also paste the example text into a text file, for example called example.txt and then apply the same command to the text file:
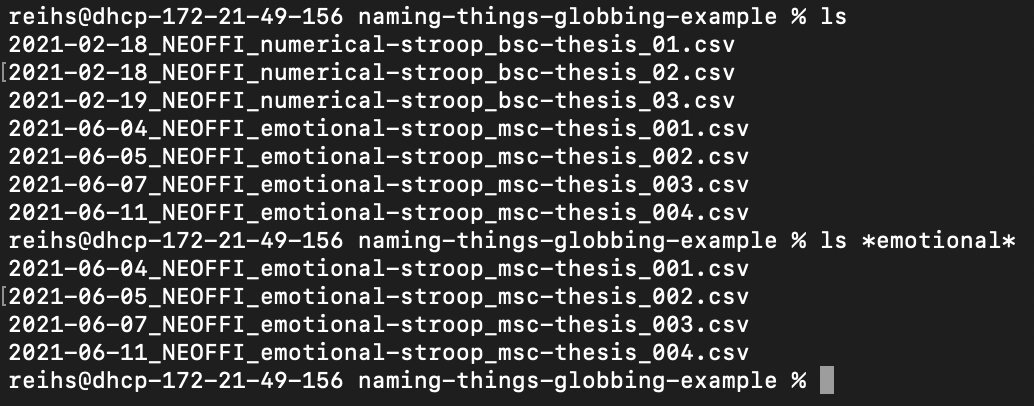
Globbing refers to the use of wildcard characters (like * and ?) to match multiple files or directories in command-line interfaces and scripting. Being globbing friendly means file names or paths are structured in a way that makes them easy to match using these wildcards.
For example, let’s assume that you have three files like YYYY-MM-DD_NEOFFI_numerical-stroop_bsc-thesis_01.csv and YYYY-MM-DD_NEOFFI_emotional-stroop_msc-thesis_01.csv. You can use a glob pattern like *emotional* to match all of your data sets associated with the emotional stroop task.
This screenshot was made by Justus Reihs on a MacBook. Used under a CC-BY 4.0 license.
3.4.3 Recover meta data from file names
Metadata is information that describes key details about a file, like the date it was created, the author, or the type of data it contains. Including metadata in a filename (for example, 2023_Experiment1_DrSmith.csv) is helpful because it makes important details visible at a glance. This helps with organizing, searching, and sorting files, especially in large projects where you may have many similar files. By storing metadata in filenames, you can quickly understand what each file contains without opening it, saving time and reducing errors in data management.
3.4.3.1 How to recover meta data from file names
Deliberate use of underscores (_) and hyphens (-) allows us to recover metadata from file names.
Use underscores (_) to delimit units of metadata
Use hyphens (-) to delimit words to improve human readability
Names are more easily machine-readable if they are:
Easy to search for files later.
Easy to narrow file lists based on names.
Easy to extract information from file names, for example, by splitting them.
3.5 Human readable
Names of files and folders should contain information about its content. It should make it easy to figure out what something is based on the file name. This idea connects to the concept of a slug from semantic URLs.
NoteWhat is a slug in a URL?
A slug is a part of a URL that is easy to read and understand. It usually comes after the main website address and describes the content of the page in simple words. Slugs are important for both humans and search engines because they give a clear idea of what the page is about.
For example:
The full URL might be: https://www.example.com/blog/how-to-cook-pasta
The slug in this URL is: how-to-cook-pasta
Good slugs are short, descriptive, and use hyphens to separate words. This makes the URL more user-friendly and helps search engines understand the page content.
You can find and organize files more easily when you name them consistently.
Sometimes, file names might be in multiple languages.
For example, you may study in the Netherlands or Germany, but your research project involves international colleagues, so the common language is English.
It is recommended to name your files in only one language that everyone involved can understand.
Even if you use just one language, regional differences can lead to variations in spelling.
For example, the English word “behavior” is spelled with a u in British English (“behaviour”) but without it in American English (“behavior”).
Decide as a team on a single language and spelling style for naming files and folders.
Be mindful of capitalization as well, and choose a consistent style!
Filenames should be designed to work well with default ordering (like alphabetical or chronological order) so that files are easy to locate and understand at a glance Good ordering lets related files appear together, saves time when searching, and keeps files organized, especially in large projects.
ImportantWhen keeping copies of the same or similar files, consider version control!
Consider the use of chronologically ordered files and folders! For specifying different versions of the same document, version control tools as Git and GitHub should be preferred. Otherwise you might feel as the person in the cartoon in Figure 6.2 writing on his “final document”. For different but similar files, a chronological order can make sense.
In 1988, to avoid confusion, the International Organization for Standardization (ISO) set a global standard numeric date format, known as ISO 8601: YYYY-MM-DD, where YYYY stands for the year, e.g., 2024, MM stands for the month, e.g., 11, and DD stands for the day, e.g., 06. Using the ISO 8601 standard for dates (like 2023-11-06) ensures consistency and avoids confusion. This format starts with the year, followed by the month, and then the day, which makes it easy to sort dates in the correct order. It works well across different cultures and software, helping everyone read and organize dates the same way.
Files that are later turned into HTML should be exclusively delimited by hyphens (-).
3.7.2 Left-pad numbers with zeros
Left-padding of numbers refers to the practice of adding zeros to the left of a number to make it reach a certain length. This can be useful, for example, when dealing with numerical data that needs to be formatted in a specific way for presentation or computational purposes. By left-padding numbers, you can ensure that they all have the same length and are easier to compare or work with in a numerical context.
When left-padding numbers, you can add as many leading zeros as you might need. In many cases, using one zero (i.e., 01) will be sufficient but you might also have more files, you could consider left-padding with two zeros (i.e., 001) if the number of relevant files go to or beyond a hundred.
3.8 Summary
Here is a summary of all recommendations for naming things:
3.8.1 Machine readable
File names are regular expression and globbing friendly
File names allow to recover meta data
3.8.2 Human readable
File names contain info on content
3.8.3 Consistency
File names are named in one language
Be aware of regional influences in spelling
Consistent use of upper and lower case
3.8.4 Plays well with default ordering
Put something numeric first
Use the ISO 8601 standard for dates: YYYY-MM-DD
Left pad other numbers with zeros: e.g., 01
3.9 References
We would like to express our gratitude to the following resources which have been essential in shaping this chapter. We recommend these references for further reading.
Gorgolewski, Krzysztof J., Tibor Auer, Vince D. Calhoun, R. Cameron Craddock, Samir Das, Eugene P. Duff, Guillaume Flandin, et al. 2016. “The Brain Imaging Data Structure, a Format for Organizing and Describing Outputs of Neuroimaging Experiments.”Scientific Data 3 (1). https://doi.org/10.1038/sdata.2016.44.